Gigascience:拥抱大数据复杂性的生命科学人工智能应用新篇章
19小时前 MedSci原创 MedSci原创 发表于威斯康星

人工智能(AI)正成为生命科学研究的核心工具,尤其在多组学大数据的解析中展现出独特优势。
Highlight
- 人工智能(AI)正成为生命科学研究的核心工具,尤其在多组学大数据的解析中展现出独特优势。
- ML与DL技术助力植物学、动物学及微生物学领域,推动从基因组学到表型组学的融合分析。
- FAIR原则(数据可查找、可获取、可互操作和可重复使用)为多组学数据管理和AI应用提供保障,促进研究的开放性和重复性。
研究核心概述
近年来,伴随着高通量测序和组学技术的迅猛发展,生命科学进入了大数据时代。而人工智能(AI),尤其是机器学习(ML)和深度学习(DL),正逐渐成为解码这些复杂数据不可或缺的工具。本文综述了AI如何通过对植物学、动物学和微生物学等领域多组学数据的分析,帮助揭示生物系统的复杂性与内在联系,同时讨论了数据整合、模型解释性以及未来挑战等关键问题。该论文发表于权威期刊GigaScience,体现了当前AI技术在生命科学中的广泛应用和巨大潜力。
研究背景与科学问题
进入21世纪后,生命科学数据产生量呈指数级增长,尤其是来自基因组学、转录组学、蛋白质组学和代谢组学等多组学实验。高通量测序技术(NGS)、高分辨质谱技术(HRMS)等推动了这一趋势,而随之而来的庞大而复杂的生物数据对传统分析方法提出了严峻挑战。
人类大脑难以直接处理由数十万甚至数百万分子变量组成的高维数据,以及它们和生物表型之间错综复杂的关联。由此,基于计算能力和算法发展的AI技术应运而生,不仅能提升数据分析深度,也有望加速发现过程。
在此背景下,生物数据的各种异质性、多维度集成以及结果的可解释性成为亟须突破的瓶颈。同时,遵循FAIR原则的规范化数据管理成为保障研究可重复性和协作的重要保障。
主要研究内容及成果详解
1. 生命科学大数据爆发与AI应答
20年来,NGS技术极大丰富了动物和植物基因组测序数据,同时转录组测序(RNA-seq)、蛋白质组学及代谢组学也借助质谱技术得到飞速发展。以往分散的单组学数据逐渐整合,形成多层次生物系统全貌。
同时,自动化成像技术和传感器技术(如多光谱、热成像等)在植物表型组学中广泛应用,实现了非侵入式高通量表型数据获取,为AI算法提供了丰富输入源。
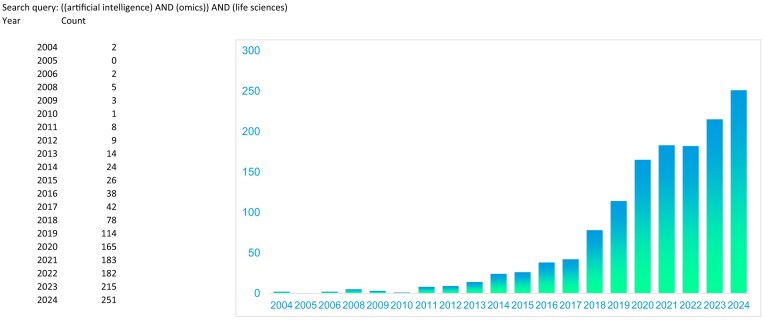
图1 2004年至2024年间,PubMed检索含“artificial intelligence”、“omics”和“life sciences”关键词相关出版物数量,显示人工智能对组学生物学影响的迅速增长。
2. AI、机器学习与深度学习技术框架
AI强调从数据中学习规律并应用于新数据预测,其中机器学习(ML)尤其突出。ML包括“有监督学习”与“无监督学习”:前者利用带标签数据进行训练,后者侧重数据结构和内在规律挖掘。深度学习(DL),作为基于人工神经网络的新型ML分支,自2006年兴起,尤其适合处理图像和复杂非线性生物数据。
关键算法包括:
- 线性回归:解释输入输出线性关系,易于理解,常用于基因表达分析。
- 支持向量机(SVM):通过最大化间隔实现二分类,利用核函数实现非线性映射。
- 决策树及其集成(随机森林、梯度提升树):规则明确,具良好解释性。
- 朴素贝叶斯分类器:概率模型,适合简单分类但假设独立性较强。
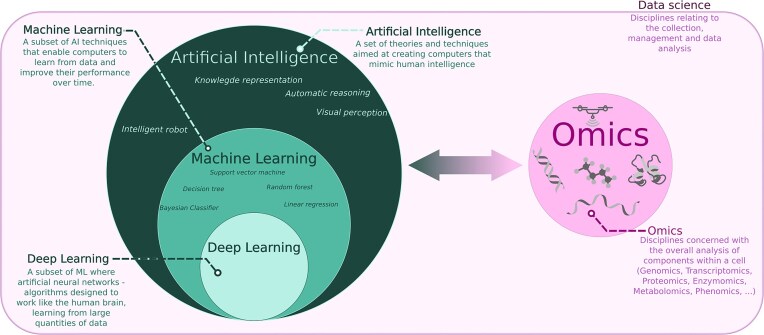
图2 人工智能领域中机器学习与深度学习的层级及应用关系示意图。
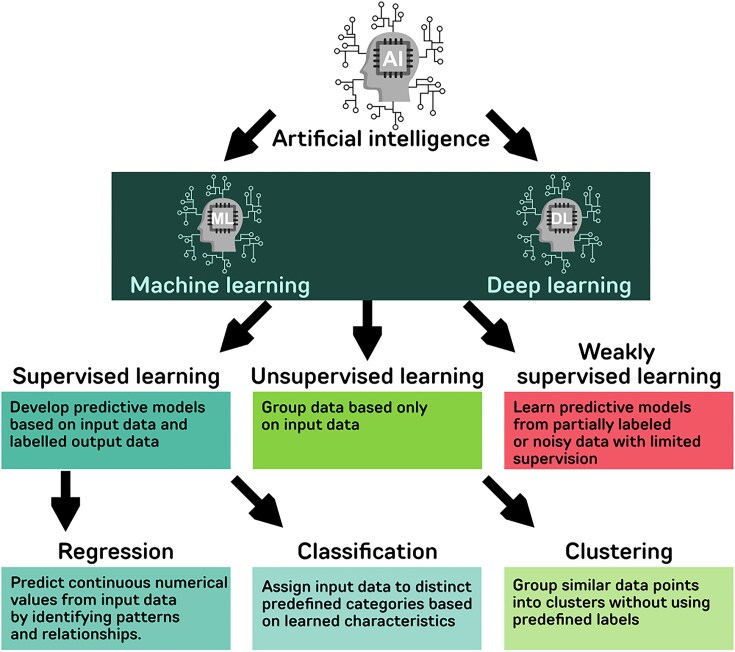
图3 展示主要的机器学习与深度学习方法,包括监督学习、非监督学习及强化学习。
3. 多组学数据集成与预测分析
多组学融合能够综合各组学层面信息,提高对复杂生物现象的认知与预测准确性。本文介绍了多种统计和机器学习方法实现数据融合,如综合正交部分最小二乘判别分析(OPLS-DA)、多核学习与基于R语言的mixOmics等工具,结合网络扩散和深度学习进一步挖掘非线性关系。
4. AI在植物科学中的应用实践
植物科学因高维组学数据而亟需AI技术。基于高通量表型图像,卷积神经网络(CNN)等DL算法能够快速准确地鉴定植物的生物胁迫及病害,提升病害诊断效率。根系结构分析的新兴AI应用助力“第二次绿色革命”。基因组预测(GP)结合ML模型,尤其代谢组数据,显著提升植物性状预测性能,辅助育种决策。
5. AI推动动物科学数据分析升级
动物遗传改良越来越依赖组学数据融合,包括基因、转录、代谢及表型数据。机器学习模型(如随机森林、梯度提升树)有力辅助疾病鉴别和饲料效率预测。代谢组无目标数据借助AI实现健康状态精准分类。禽畜抗菌药物耐药性预测为公共卫生安全提供数据支撑。
6. 微生物组学中的AI应用探索
天然微生物群落的复杂互作及其环境适应性成为AI关注热点。16S rRNA测序为基础,被广泛用于微生物分类与生态预测,随机森林等算法因兼顾准确性与解释性而被大量采用。综合基于贝叶斯网络的微生物间协同作用预测,为生物过程优化提供策略。
生命科学AI研究面临的挑战及未来展望
| 主要技术挑战 | 描述 | 与ML/DL关联 |
|---|---|---|
| 噪声数据 | 错误数据影响预测准确性,需先进预处理。 | ML对噪声敏感,DL表现更受影响。 |
| 高维度 | 特征过多引发过拟合,需特征选择。 | ML采用外部选择,DL深度融合特征。 |
| 多组学数据整合 | 异构数据标准不一,综合困难。 | ML需多种方法融合,DL追求端到端学习。 |
| 结果可解释性 | 黑盒模型难以阐释决策依据。 | ML较易解释,DL解释技术仍在发展。 |
| 计算资源需求 | 大模型训练耗时耗能。 | DL资源消耗更甚。 |
| FAIR原则 | 数据难以完全遵循标准化管理。 | FAIR促进ML、DL研究开放与复现。 |
| 数据规模与多样性 | 数据偏倚影响模型泛化能力。 | ML需考虑样本分布,DL更依赖大样本。 |
尤其值得关注的是标注数据的获取难题。深度学习模型需大量带标注的数据,然而生物领域数据标注消耗巨大,弱监督和半监督学习方法成为突破口。此外,元数据规范化(借助本体论)、数据共享与隐私保护亦是未来发展重点。
在代谢物注释和基因功能预测领域,基于CNN和神经网络的模型如“DeepMet”和“DeepGOPlus”已表现出强大潜力,但标准化评测和广泛应用仍需推进。
结论与研究意义
本综述强调了人工智能技术特别是机器学习和深度学习在生命科学领域的广泛应用与重要价值。多组学数据的有效整合和智能分析不仅加深了对生物系统复杂性的认知,也推动了植物育种、动物遗传改良和微生物生态学的进步。随着技术成熟和FAIR理念的推广,AI必将在基础研究和应用领域发挥更大作用,助力生命科学迈入精准与智能化新时代。
梅斯编辑点评
这篇综述文章系统地梳理了生命科学大数据挑战及AI应对策略,特别强调了从多组学集成到模型解释性的技术难点。结合具体领域案例,文章不仅展示了AI现有的应用成效,更深刻剖析了未来转化与推广中亟待解决的问题。对科研人员来说,是一份极具指导价值的前沿报告,鼓励跨学科合作,推动AI与生命科学更加紧密结合,助力数字生物学发展。
参考文献(原始出处部分选录)
-
Melandri G, Radohery GR, Beaumont C, et al. Artificial intelligence: the human response to approach the complexity of big data in biology. GigaScience. 2025;14:giaf057. doi:10.1093/gigascience/giaf057.
-
Stephens ZD, Lee SY, Faghri F, et al. Big data: astronomical or genomical? PLoS Biol. 2015;13:e1002195.
-
Wang Z, Gerstein M, Snyder M. RNA-seq: a revolutionary tool for transcriptomics. Nat Rev Genet. 2009;10:57–63.
-
Lecun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521:436–44.
原始出处:
Melandri G, R-Radohery G, Beaumont C, de Cripan SM, Muller C, Piras L, Pereira MA, Salvador AF, Domingo-Almenara X, Bolger M, Colombié S, Prigent S, Arechederra BG, Canela NC, Pétriacq P. Artificial intelligence: the human response to approach the complexity of big data in biology. Gigascience. 2025 Jan 6;14:giaf057. doi: 10.1093/gigascience/giaf057. PMID: 40504538; PMCID: PMC12160488.

本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言














#人工智能# #多组学大数据# #FAIR原则#
8